
Description
Классификация сканирования документов
Работа с бумажными записями представляет собой еще одну проблему в рамках классификации документов. Сначала мы должны отсканировать их, а затем извлечь написанный или напечатанный текст для дальнейшего анализа. Необходимая для этих целей технология должна распознавать текст и его макет с изображений и сканов, что облегчает преобразование бумажных документов в цифровой формат и последующую их классификацию.
Например, индустрия здравоохранения по-прежнему имеет дело с бумажными документами. Оцифровка медицинских отчетов и других документов является одной из важнейших задач для медицинских учреждений по оптимизации их документооборота. Из-за строгих правил и высоких стандартов точности автоматизация обработки документов становится сложной. Но некоторые организации здравоохранения, такие как FDA , применяют различные методы классификации документов для ежедневной обработки тонн медицинских архивов.
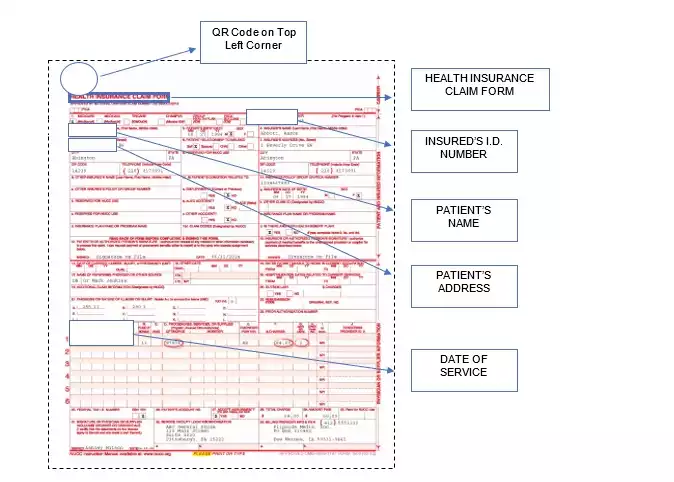 Пример структуры документа в медицинском страховании
Пример структуры документа в медицинском страховании
Другим примером является страховая отрасль, которая ежедневно обрабатывает десятки тысяч требований. Но он страдает от неэффективного рабочего процесса, поскольку большинство претензий поступает в виде сканов. Это требует автоматического извлечения необработанных данных из требований и применения NLP для анализа. Например, Wipro , поставщик программного обеспечения, предоставляет классификатор NLP для обнаружения поддельных требований в страховом секторе.
Распознавание объектов компьютерным зрением
Распознавание объектов можно применять в сферах бизнеса, требующих обработки больших объемов визуальных данных для их классификации по категориям. В основном это задача управления запасами, где изображения изображают продукты, которые необходимо классифицировать.
Например, Scalr разработал программное обеспечение для распознавания изображений, реализованное в Ecommerce, которое автоматизирует классификацию типов продуктов.
Это некоторые бизнес-кейсы, в которых классификация документов может применяться в различных формах, чтобы дать общее представление о том, когда ее можно использовать. Теперь поговорим о том, как работает классификация документов в конкретных случаях, и остановимся на выборе технологии более подробно.
Визуальная классификация с компьютерным зрением
Компьютерное зрение (CV) — это технология искусственного интеллекта для распознавания объектов на неподвижных изображениях или видео. Распознавание изображений можно использовать в классификации документов для обнаружения объектов, их местоположения или поведения в визуальном контенте. Это дает нам возможность классифицировать фотографии и видео, а также применять фильтрацию и поиск.
Существует несколько задач классификации, которые могут решать системы компьютерного зрения.
Классификация изображений с локализацией – идентификация объекта на изображении и отметка его местоположения. Этот метод можно применять для классификации отсканированных документов на основе их структуры, например, для различения документов с 5 полями для заполнения и документов с 3 полями.
Обнаружение объектов — распознавание и маркировка нескольких объектов на изображении и отображение местоположения каждого объекта. Например, классификация пользовательского визуального контента. Туристические платформы могут определять изображения, содержащие меню ресторана, интерьеры и т. д.
Объектная (семантическая) сегментация — идентификация конкретных пикселей, принадлежащих каждому объекту на изображении. Например, обнаружение нарушений на рентгеновских снимках и их классификация в зависимости от того, требуют ли они внимания врача.
Сегментация экземпляров — дифференциация нескольких объектов одного класса. Например, называя породу собак, людей, вид дерева и т.
Этот тип классификации не считается текстовой классификацией, даже если он имеет дело с документами, поскольку он анализирует пиксельную структуру изображения и пытается определить, как текстовые блоки или поля расположены на поле.

Пример классификации компьютерного зрения для распознавания различных элементов документа.
Технологии распознавания изображений работают на глубоких нейронных сетях — вычислительных системах, предназначенных для распознавания образов. В этом случае нейронная сеть обучается специально анализировать пиксельные паттерны, из которых состоит объект на изображении. Обучение нейронных сетей и их внедрение в ваш классификатор может быть сложной задачей, поскольку для этого требуются знания в области глубокого обучения и довольно большие наборы данных.
Итак, по этой причине мы можем использовать API-интерфейсы распознавания изображений, доступные в Интернете. Эти API предоставляют возможности компьютерного зрения вашему программному обеспечению, позволяя выполнять классификацию визуального контента. Вы можете проверить наш список API распознавания изображений, чтобы узнать о некоторых из них.
Классификация текстов
В большинстве случаев классификация касается текстовой информации, поскольку предприятия и организации полагаются на текстовые документы в повседневных операциях. Существует несколько сценариев реализации классификатора.
Имейте в виду, что вы не можете классифицировать тексты до того, как они будут оцифрованы. Итак, если у вас есть отсканированные или физические документы, вам необходимо сначала оцифровать их с помощью оптического распознавания символов.
Оцифровка документов и текстов с помощью OCR
Классификация документов может включать физические документы, поскольку в таких отраслях, как банковское дело , страхование и здравоохранение , огромное количество документов все еще находится на бумаге. Это заставляет предприятия создавать сложные рабочие процессы для преобразования рукописных или напечатанных данных в цифровой формат для классификации и других задач.
Оптическое распознавание символов (OCR) — это технология, позволяющая обнаруживать и извлекать текстовую информацию из отсканированных документов. Как только текст распознан и оцифрован, он становится пригодным для дальнейшей обработки. Здесь мы рассмотрим некоторые сценарии того, как работают базовые и более продвинутые подходы к классификации текста.
Классификация текста на основе правил: обнаружение и подсчет ключевых слов
Основным способом классификации документов является построение системы, основанной на правилах. Такие системы используют сценарии для запуска задач и применения набора правил, созданных человеком.
Разграничение категорий документов . Прежде чем приступить к любой системе классификации документов, первым шагом будет сбор существующих данных и их анализ, чтобы понять, какие классы элементов существуют. Допустим, мы проанализировали набор из 50 статей о здоровье и увидели, что все они относятся к 3 категориям: психология, питание и спорт.
Система, основанная на правилах, будет использовать эти категории в качестве основных входных данных для классификации новых документов в будущем.
Определение ключевых слов . Чтобы классифицировать документы, нам нужно извлечь специфичные для предметной области слова, которые обычно встречаются в этой теме.
Проанализировав, скажем, 20 статей по психологии, мы можем обнаружить, что такие слова, как «депрессия», «тревога», «синдром», «психический» и «мысль», используются часто. Такой же анализ проводится с категориями питания и спорта. В результате мы собираем набор признаков (ключевых слов) для каждой категории.

Список ключевых слов, относящихся к определенным категориям статей
На этом этапе мы формируем список ключевых слов, которые помогут нам определить, относится ли статья к данной теме. Основанный на правилах механизм, состоящий из скриптов, будет сканировать документы и находить релевантные ключевые слова для подсчета. В результате он будет оценивать каждую статью по количеству найденных ключевых слов.
Системы на основе правил просты в реализации и могут выполнять множество рутинных задач классификации. Например, если у вас есть набор стандартных документов, таких как счета и квитанции, вы можете классифицировать их, проверив, содержит ли первая строка такие ключевые слова, как «счет-фактура» и «квитанция».
Тем не менее, вы должны знать определенные правила. Прекрасно, если вы знаете критерии классификации. Но как только задача выходит за рамки простого подсчета ключевых слов, становится все труднее придумать исчерпывающие и окончательные принципы классификации.
Классификация официальных документов по типу — самый простой пример, когда системы, основанные на правилах, могут работать хорошо. Когда дело доходит до сложных задач, таких как определение эмоций в тексте или обнаружение спама, системы, основанные на правилах, сталкиваются со своими ограничениями.
Классификация машинного обучения с обработкой естественного языка (NLP)
Работа с более сложными задачами классификации текста требует обработки естественного языка или НЛП . НЛП находится на пересечении нескольких дисциплин — лингвистики, статистики и компьютерных технологий, которые позволяют компьютерам понимать человеческий язык в контексте. С помощью NLP классификаторы документов могут определять шаблоны в текстах или даже понимать значение слов — вроде того.
NLP — это технология машинного обучения, что означает, что для обучения модели требуется много данных, но она помогает решать более сложные задачи классификации текста, такие как анализ комментариев, статей, обзоров и других медиа-документов.
В отличие от созданной человеком логики «если-то», которую мы пишем для систем, основанных на правилах, модели машинного обучения обучены автоматически распознавать категории. Обучение машинному обучению предполагает, что мы передаем в модель прошлые данные с предопределенными категориями и набором функций, чтобы изучить статистические связи между словами и фразами.
С помощью обработки естественного языка модели машинного обучения могут обеспечить высокую степень автоматизации анализа текста, будучи гораздо более точными и гибкими, чем системы, основанные на правилах. Итак, теперь давайте рассмотрим создание классификаторов на основе ML.
Определение категорий и сбор обучающего набора данных . Прежде чем модель сможет классифицировать какие-либо документы, ее необходимо обучить на исторических данных, помеченных метками категорий. Мы можем пометить существующие документы для использования в качестве нашего обучающего набора данных.
Обратите внимание, что для получения достоверных результатов требуется большой объем размеченных данных. Если у вас недостаточно документов или ресурсов для их маркировки, вы можете искать соответствующие наборы данных в бесплатных библиотеках, таких как общедоступные данные Google BigQuery или Paperswithcode .
Тем не менее, есть вероятность, что вы не найдете подходящего для вашей конкретной задачи в открытых источниках. Учитывая важность правильной маркировки, рассмотрите другие варианты — например, обратитесь в компании, специализирующиеся на подготовке данных. Прочтите наши статьи о маркировке данных и о том, как организовать маркировку данных для машинного обучения , чтобы получить дополнительную информацию.
Предварительная обработка данных или документов в данном случае означает, что они должны быть осуществимы и предсказуемы. Это включает в себя множество операций, таких как перевод всех слов в нижний регистр, преобразование их в корневую форму (walking — ходить) или оставление только корня. Затем документ может быть также очищен от стоп-слов (и, тот, есть, есть) и нормализован, объединив разные формы одних и тех же слов (окей, ок, кк).
Хотя выполнять задачи предварительной обработки не обязательно, проекты машинного обучения, требующие высокой точности, обычно включают такую подготовку. Это значительно упрощает переваривание данных алгоритмом в процессе обучения. Это особенно важно, когда мы говорим о системах, основанных на НЛП, и о проектах анализа настроений.
Извлечение признаков или векторизация — это процесс преобразования текста в его числовое (векторное) представление. Основная техника извлечения признаков называется набором слов . Он представляет каждое предложение в виде строки чисел, основанной на простом принципе появления (или отсутствия) определенных ключевых слов.
Более сложные подходы к векторизации, такие как латентный семантический анализ (LSI), Word2Vec или GloVe (глобальные векторы), могут анализировать контекстное использование ключевых слов, фиксировать семантические отношения и точно определять фразы с одинаковым значением. Например, предложения «У него не хватало денег» и «У него не было достаточно денег» передают одну и ту же мысль. Преобразование этих фраз в наборы векторов является одним из методов анализа текста для сравнения семантических конструкций и поиска сходства в содержании.
Обучение модели . Существует множество алгоритмов, применимых к задачам классификации документов. Популярными вариантами являются наивный байесовский метод и метод опорных векторов (SVM), поскольку они не требуют больших объемов обучающих данных для получения точных результатов.
Во время обучения модель научится определять, как данные признаки соотносятся с категориями. В примере алгоритма машины опорных векторов процесс обучения можно представить в виде гиперплоскости.

Гиперплоскость машины опорных векторов
По сути, он разделяет наши векторы обучения на два подпространства: одно для документов, относящихся к теме «психология», а другое — для всего остального. Анализируя оценки векторов, модель SVM ищет наибольшую разницу между учебными документами. Это поле обозначает оптимальную разницу между статьями по психологии и непсихологии. И он применит полученные результаты для классификации новых документов.
Мы исследовали различные способы классификации документов по предопределенным категориям. Но что, если эти категории неизвестны? Что делать, если нам нужно отсортировать документы нескольких типов из разных источников? Рассмотрим варианты решения этой задачи.
Неконтролируемая классификация: определение категорий
Во всех предыдущих случаях мы контролируем наши классификаторы либо с помощью правил (в системах, основанных на правилах), либо с помощью меток категорий, назначенных обучающим данным (в системах, основанных на машинном обучении). Тип машинного обучения, при котором мы вводим данные (определяем существующие категории): называется обучением с учителем . Но это не работает для сценариев, когда мы понятия не имеем о критериях классификации. Кроме того, даже если категории определены, аннотирование большого количества учебных документов требует много времени и усилий. Вот когда неконтролируемое машинное обучение может помочь.
Алгоритмы неконтролируемой классификации или кластеризации не требуют для своей работы помеченных наборов данных. Они обнаруживают сходство в документах и соответствующим образом организуют их в группы (кластеры). В результате объекты из одного кластера будут иметь больше общих характеристик (например, ключевых слов), чем в разных кластерах.
Неконтролируемая классификация текста . Применяя НЛП для понимания контекста слов, модель может сканировать существующий набор данных и находить сходство между документами. Затем он делит набор похожих документов на кластер. Этот кластер будет содержать записи с содержимым, которое теоретически попадает в одну и ту же категорию.
Неконтролируемая классификация изображений . Модели неконтролируемого обучения также можно использовать для обнаружения повторяющихся шаблонов в изображениях и выполнения кластеризации на основе схожих свойств. Это может быть случай классификации объектов: модель обучается обнаруживать объекты на изображении, а затем определять, к какому классу она относится. Подобно кластеризации в текстовой классификации, неконтролируемым моделям потребуется довольно большой объем данных, чтобы научиться различать типы объектов и существующие объекты.
Гибридный подход к классификации документов
Выбор технологии классификации документов зависит от конкретной задачи, которую необходимо решить. Однако чаще всего лучший вариант предполагает сочетание разных методов.
Одной из реализаций такого гибридного подхода является система, созданная для юридической компании Berry Appleman & Layman. Он сочетает в себе компьютерное зрение и OCR для классификации документов иммигрантов . Во-первых, программа классифицирует изображения обычных документов по их структуре (например, паспорта, свидетельства о рождении и т. д.). Во-вторых, он применяет OCR для «чтения» запросов о доказательствах или RFE. После того, как текст из RFE извлечен и оцифрован, выполняется операция копирования и вставки для создания черновика документа, который юристы используют в дальнейшей работе.
Другим примером является клиническая классификация текстов с помощью сверточных нейронных сетей и функций, основанных на правилах . Весь процесс включает три шага: 1) определение триггерных фраз, содержащих названия болезней, с использованием правил; 2) предсказание классов на основе триггерных фраз; 3) обучение CNN классифицировать медицинские записи. Хотя этот классификатор существует как исследовательский проект, он подает большие надежды и может стать основой для реальной системы.
Если у Вас появилась заинтересованность в данной нейронной сети, и она может помочь Вам в реализации Ваших бизнес и других технических задачах, пожалуйста отправьте заявку на email info@ai2b.ru , или позвоните по телефону 8(495)661-61-09




Reviews
There are no reviews yet.