
Description
Использование машинного обучения для поиска уязвимостей в системе безопасности.
Заглянуть за кулисы в структуру машинного обучения, обеспечивающую новые предупреждения системы безопасности при сканировании кода.

Сканирование кода GitHub теперь использует машинное обучение (ML), чтобы предупредить разработчиков о потенциальных уязвимостях безопасности в их коде.
Если вы хотите настроить свои репозитории для отображения большего количества оповещений с помощью нашей новой технологии машинного обучения, начните здесь . Читайте дальше, чтобы заглянуть за кулисы фреймворка машинного обучения, лежащего в основе этой новой технологии!
Обнаружение уязвимого кода
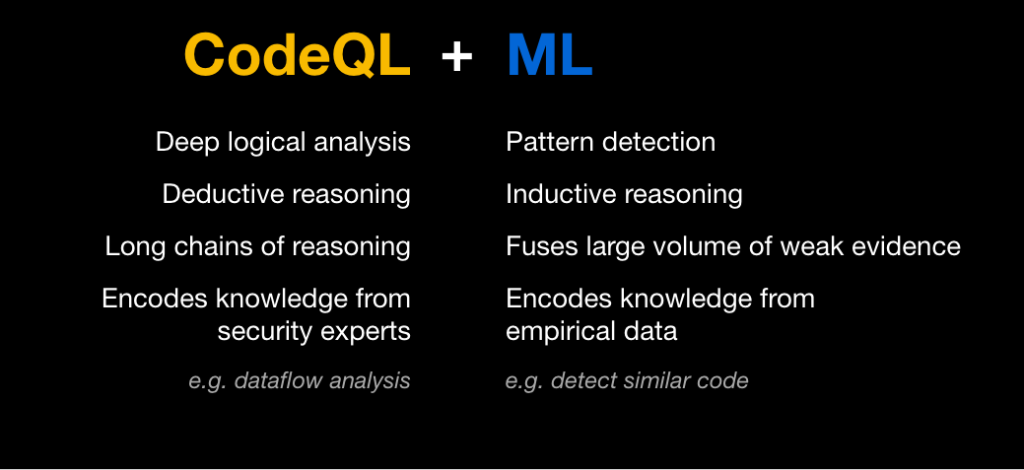
Уязвимости безопасности кода могут позволить злоумышленникам манипулировать программным обеспечением, чтобы оно вело себя непреднамеренным и вредоносным образом. Лучший способ предотвратить такие атаки — обнаружить и исправить уязвимый код до того, как его можно будет использовать. Возможности сканирования кода GitHub используют механизм анализа CodeQL для поиска уязвимостей в системе безопасности в исходном коде и поверхностных предупреждений в запросах на включение до того, как уязвимый код будет объединен и выпущен.
Для обнаружения уязвимостей в репозитории механизм CodeQL сначала создает базу данных, которая кодирует специальное реляционное представление кода. Затем в этой базе данных мы можем выполнить серию запросов CodeQL, каждый из которых предназначен для поиска определенного типа проблемы безопасности.
Многие уязвимости вызваны одним повторяющимся шаблоном: ненадежные пользовательские данные не очищаются и впоследствии случайно используются небезопасным образом. Например, SQL-инъекция вызвана использованием ненадежных пользовательских данных в SQL-запросе, а межсайтовые сценарии возникают в результате записи ненадежных пользовательских данных на веб-страницу. Для обнаружения ситуаций, в которых небезопасные пользовательские данные попадают в опасное место, запросы CodeQL инкапсулируют знания о большом количестве потенциальных источников пользовательских данных (например, веб-фреймворков), а также о потенциально опасных приемниках (таких как библиотеки для выполнения SQL). запросы). Члены сообщества безопасности вместе с экспертами по безопасности на GitHub, постоянно расширяйте и улучшайте эти запросы для моделирования дополнительных общих библиотек и известных шаблонов. Однако ручное моделирование может занять много времени, и всегда будет длинный хвост менее распространенных библиотек и частного кода, который мы не сможем смоделировать вручную. Здесь на помощь приходит машинное обучение.
Мы используем примеры, полученные с помощью ручных моделей, для обучения нейронных сетей глубокого обучения, которые могут определить, содержит ли фрагмент кода потенциально опасный приемник.
В результате мы можем обнаруживать уязвимости безопасности, даже если они возникают из-за использования библиотеки, которую мы никогда раньше не видели. Например, мы можем обнаруживать уязвимости SQL-инъекций в контексте малоизвестных библиотек абстракций баз данных или библиотек с закрытым исходным кодом.
Создание тренировочного набора
Нам нужно обучить модели машинного обучения распознавать уязвимый код. Хотя мы экспериментировали с неконтролируемым обучением, неудивительно, что мы обнаружили, что контролируемое обучение работает лучше. Но это дорогого стоит! Просить экспертов по безопасности кода вручную помечать миллионы фрагментов кода как безопасные или уязвимые явно несостоятельно. Итак, где мы берем данные?Написанные вручную запросы CodeQL уже воплощают в себе опыт многих экспертов по безопасности, которые их написали и усовершенствовали. Мы используем эти ручные запросы как наземные оракулы, чтобы пометить примеры, которые мы затем используем для обучения наших моделей. Каждый обнаруженный таким запросом сток служит положительным примером в обучающей выборке. Поскольку подавляющее большинство фрагментов кода не содержат уязвимостей, фрагменты, не обнаруженные ручными моделями, можно рассматривать как негативные примеры. Мы компенсируем шум, присущий этой предполагаемой маркировке, с помощью громкости. Мы извлекаем десятки миллионов фрагментов из более чем ста тысяч общедоступных репозиториев, запускаем для них запросы CodeQL и помечаем каждый как положительный или отрицательный пример для каждого запроса. Это становится тренировочным набором для модели машинного обучения, которая может классифицировать фрагменты кода как уязвимые или нет.
Конечно, мы не хотим обучать модель, которая будет просто воспроизводить ручное моделирование; мы хотим обучить модель, которая будет предсказывать новые уязвимости, которые не были обнаружены при ручном моделировании. По сути, мы хотим, чтобы алгоритм машинного обучения улучшал текущую версию ручного запроса почти так же, как текущая версия улучшает более старые, менее полные версии. Чтобы увидеть, сможем ли мы это сделать, мы на самом деле строим все наши обучающие данные из более старой версии запроса, которая обнаруживает меньше уязвимостей. Затем мы применяем обученную модель к новым репозиториям, на которых она не обучалась. Мы измеряем, насколько хорошо мы восстанавливаем оповещения, обнаруженные последним ручным запросом, но пропущенные более старой версией запроса. Это позволяет нам имитировать способность модели, обученной с помощью текущей версии запроса для восстановления предупреждений, пропущенных этой текущей ручной моделью.
Вместо того, чтобы рассматривать каждый фрагмент кода просто как строку слов или символов и наивно применять стандартные методы обработки естественного языка (NLP) для классификации этих строк, мы используем мощь CodeQL для доступа к большому количеству информации о базовом исходном коде . Мы используем эту информацию для создания богатого набора высокоинформативных функций для каждого фрагмента кода.
Одним из основных преимуществ моделей глубокого обучения является их способность объединять информацию из большого набора функций для создания функций более высокого уровня и обнаружения закономерностей, которые не очевидны для человека. В сотрудничестве с экспертами по безопасности и языкам программирования в GitHub мы используем CodeQL для извлечения информации, которую эксперт может изучить, чтобы принять решение, например полное тело прилагаемой функции для фрагмента, который находится внутри функции, или путь доступа и API. имя. Однако мы не должны ограничиваться чертами, которые человек счел бы информативными. Мы можем включать функции, полезность которых неизвестна, или функции, которые могут быть полезны в некоторых случаях, но не во всех, например индекс аргумента для фрагмента кода, который является аргументом функции. Такие функции могут содержать закономерности, невидимые для человека. но что нейронная сеть может обнаружить. Поэтому мы позволяем модели машинного обучения решать, следует ли использовать все эти функции и как их комбинировать, чтобы принять наилучшее решение для каждого фрагмента.
После того, как мы извлекли богатый набор потенциально интересных функций для каждого примера, мы размечаем их и разбиваем на части, как это обычно делается в приложениях НЛП, с некоторыми изменениями для захвата характеристик, характерных для синтаксиса кода. Мы создаем словарь из обучающих данных и передаем списки индексов в словарь в довольно простой классификатор глубокого обучения с несколькими уровнями обработки отдельных признаков, за которыми следует объединение признаков и несколько слоев комбинированной обработки. Результатом является вероятность того, что текущая выборка является уязвимой для каждого типа запроса.
Из-за масштаба нашей автономной маркировки данных, извлечения функций и конвейеров обучения мы используем облачные вычисления, включая графические процессоры, для обучения моделей. Однако во время вывода графический процессор не требуется.
Если у Вас появилась заинтересованность в данной нейронной сети, и она может помочь Вам в реализации Ваших бизнес и других технических задачах, пожалуйста отправьте заявку на email info@ai2b.ru , или позвоните по телефону 8(495)661-61-09



Reviews
There are no reviews yet.