
Description
Большая часть работы ИИ в здравоохранении сосредоточена на прогнозировании заболеваний в клинических условиях, что является важным приложением. Однако есть и другие фундаментальные аспекты. Самым большим подмножеством медицинских ошибок являются медицинские ошибки. Предоставление правильного плана лечения для пациентов включает в себя информацию об их текущих лекарствах и лекарственной аллергии, что часто является сложной задачей. Повсеместный рост назначения и потребления лекарств увеличил потребность в приложениях, поддерживающих согласование лекарств. Разработана нейронная сеть для определения принадлежности медицинского препарата определенной категории товаров на основе его описания и изображения.
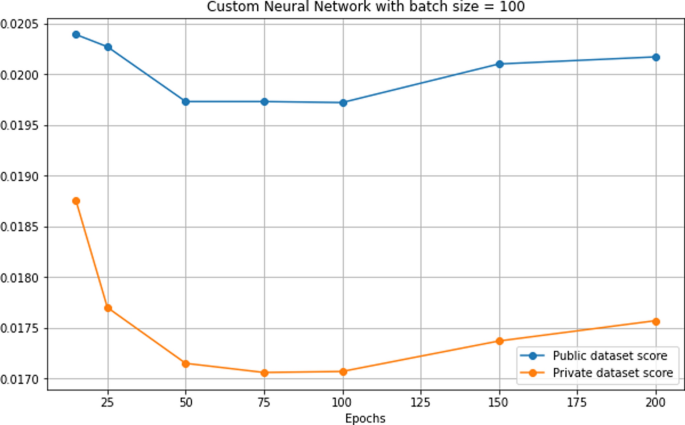
Механизм действия является важным аспектом разработки лекарств. Это может помочь ученым в процессе открытия лекарств. В этой статье представлена модель машинного обучения для прогнозирования механизма действия лекарства. Модели машинного обучения, используемые в этой статье, — это двоичная релевантность K ближайших соседей (тип A и тип B), K-ближайшие соседи с несколькими метками и пользовательская нейронная сеть. Эти модели машинного обучения оцениваются с использованием средней потери журнала по столбцам. Пользовательская модель нейронной сети имела наилучшую точность с логарифмической потерей 0,01706. Эта модель нейронной сети интегрирована в веб-приложение с использованием инфраструктуры Flask. Пользователь может загрузить пользовательский набор данных о функциях тестирования, который содержит экспрессию генов и уровни жизнеспособности клеток. Веб-приложение выведет топовые классы лекарств.
Термин «механизм действия» (MoA) относится к тому, как лекарство или другое вещество оказывает воздействие на организм. Механизм действия лекарства, например, может заключаться в том, как оно воздействует на конкретную мишень в клетке, например, на фермент, или как оно влияет на функцию клетки, например, на пролиферацию клеток. Знание механизма действия препарата может предоставить информацию о безопасности препарата и его влиянии на организм.
Большинство лекарств работают, взаимодействуя с белками хозяина или патогена. Мишенью лекарственного средства являются различные белки, и название «рецептор» используется только тогда, когда взаимодействие приводит к каскаду передачи сигнала. Рецептор — это молекула или полимерная структура, которая идентифицирует и связывает эндогенное вещество на поверхности или внутри клетки. Когда вещество вызывает обнаруживаемый физиологический или фармакологический ответ, характерный для рецептора, говорят, что оно является агонистом. Некоторые лекарства могут быть неспособны инициировать какое-либо действие самостоятельно после связывания с рецепторным участком, но они могут предотвратить действие других агонистов. Их называют Антагонистами.
Понимание механизма действия биологически активного соединения включает в себя не только идентификацию мишени, но и изучение биологической химии, происходящей до или после связывания мишени. Многие гены участвуют в механизме действия лекарств и поэтому влияют на чувствительность. Механизм действия небольшой молекулы охватывает как внутриклеточную мишень(и), так и действия, которые происходят до и после взаимодействия с мишенью.
Из-за высокого уровня сложности взаимодействия между лекарством от туберкулеза и микобактериями туберкулеза лечение туберкулеза требует адекватного понимания МОА, что имеет решающее значение для успешной доставки лекарств-кандидатов. Было намечено несколько методов исследования МоА противотуберкулезных препаратов, а также даны рекомендации по будущей разработке противотуберкулезных препаратов. В контексте патогенеза Mycobacterium tuberculosis они оценили различные платформы на предмет их сильных и слабых сторон в выяснении MOA противотуберкулезных препаратов.
Биоинформатика — это наука, которая использует несколько слоев информации, таких как данные на основе изображений, пути и экспрессия генов, чтобы помочь в понимании механизмов действия. Чтобы понять МоА, необходимо проанализировать сложные реакции биологической системы человека на медикаментозное лечение. Обсуждалось влияние биоинформатики на открытие лекарств и несколько биоинформатических методов для понимания механизмов действия.
В этой статье обсуждаются различные модели машинного обучения и их точность. Далее разрабатывается веб-приложение с использованием веб-фреймворка Flask. Для разработки этого веб-приложения используется модель машинного обучения, обладающая наибольшей точностью. Это веб-приложение может быть полезным для ученых в процессе открытия лекарств.
Методология
Сериализация и десериализация используются, чтобы избежать обучения модели с использованием обучающего набора данных каждый раз, когда новый набор тестовых данных отправляется в веб-приложение.
Как показано на рис. 1
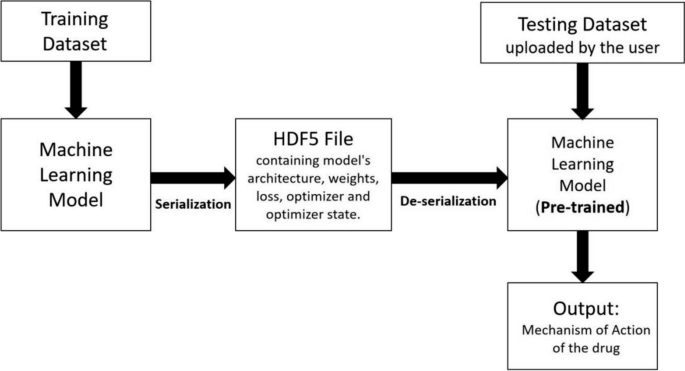
на первом этапе модель обучается с использованием обучающего набора данных. Эта модель сохраняется в файл, который присутствует в формате HDF5 HDF5 расшифровывается как Hierarchical Data Format 5. Этот процесс называется сериализацией, и это делается с помощью встроенного модуля keras «сохранить». Архитектура модели, веса, настройки обучения (потери и оптимизатор) и состояние оптимизатора содержатся в этом сериализованном файле.Позже этот файл десериализуется и передается в веб-приложение Flask. Этот процесс называется десериализацией, и он выполняется с помощью встроенного модуля keras «load_model». Таким образом, всякий раз, когда новый набор тестовых данных загружается в веб-приложение, можно избежать обучения модели с набором обучающих данных каждый раз (модель использует сериализованный файл для загрузки конфигурации предварительно обученной модели).
Как показано на рис. 2, сначала данный набор данных делится на набор данных для обучения и набор данных для тестирования. Кроме того, набор обучающих данных и набор тестовых данных были разделены на набор данных функций и целевой набор данных.

Как набор данных обучающих признаков, так и целевой набор данных обучения состоят из 23 814 обучающих выборок. Кроме того, как набор данных для тестирования, так и целевой набор данных для тестирования состоят из 3982 тестовых образцов. На этапе предварительной обработки данных категориальные значения атрибутов преобразуются в числовые значения, как показано в таблице 2.
Таблица 2 Сопоставление значений атрибута
| Имя атрибута | Старое значение | Новое значение |
|---|---|---|
| cp_type | trt_cp | 0 |
| ctl_транспортное средство | 1 | |
| cp_time | 24 часа | 0 |
| 48 ч | 1 | |
| 72 ч | 2 | |
| cp_dose | Д1 | 0 |
| Д2 | 1 |
Оценка модели машинного обучения
Точность модели машинного обучения оценивается путем применения функции логарифмических потерь для каждой пары аннотаций лекарство-МоА. Для оценки модели используется средняя логарифмическая потеря по столбцам.
Для каждого идентификатора образца «sig_id» необходимо предсказать вероятность того, что образец дал положительный ответ для каждой цели MoA. Положительный ответ означает, что лекарство принадлежит к определенному классу лекарств (т.е. мишени). Меньшее значение логарифмической потери (т. е. оценка) указывает на лучшую точность.
Формула для оценки модели машинного обучения показана в уравнении.
где: N — количество наблюдений sig_id в тестовых данных (i = 1,2,…,N). M — количество засчитанных мишеней MoA (m = 1,2,…,M). — прогнозируемая вероятность положительного ответа MoA для идентификатора образца (sig_id). — основная истина, 1 для положительного ответа, 0 в противном случае. log() — логарифм по натуральному основанию e.у^я , мy^i,mуя , м
Модели и результаты
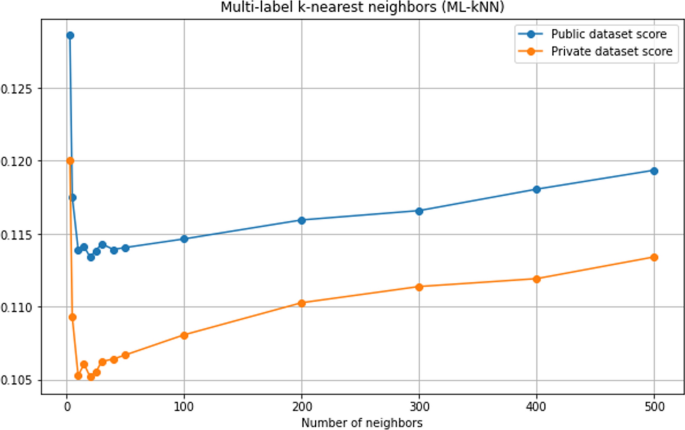
В наборе данных может быть множество механизмов действия (MoA) для каждого препарата. Таким образом, эта задача машинного обучения относится к многоуровневой классификации. Машинные модели, протестированные в этой статье, — это BRkNN (бинарная релевантность K ближайших соседей), ML-KNN (многометочная K-ближайшие соседи) и пользовательская нейронная сеть.
BRKNN (бинарная релевантность K ближайших соседей)
BRkNN — это вариант метода k-ближайших соседей (kNN), который по сути эквивалентен сочетанию двоичной релевантности (BR) с алгоритмом kNN. BRkNN расширяет метод kNN, чтобы делать независимые прогнозы для каждой метки.
На основании оценки достоверности каждой метки BRKNN подразделяется на два типа: BRkNN-a и BRkNN-b.
БРкНН-а (тип А)
BRkNN-a определяет, возвращает ли BRkNN пустой набор, если ни одна из меток не встречается по крайней мере в половине из k ближайших соседей. Если этот критерий соблюдается, выводится метка с наивысшей достоверностью .Для этой модели на рис.3 и графике 3
показаны график и оценки прогноза соответственно.

| Количество соседей | Оценка частного набора данных | Оценка общедоступного набора данных |
|---|---|---|
| 3 | 0,10773 | 0,11688 |
| 5 | 0,10518 | 0,11427 |
| 10 | 0,10605 | 0,11389 |
| 15 | 0,10651 | 0,11406 |
| 20 | 0,10709 | 0,11423 |
| 25 | 0,10733 | 0,11444 |
| 30 | 0,10801 | 0,11456 |
| 40 | 0,10898 | 0,11465 |
| 50 | 0,1095 | 0,11515 |
| 100 | 0,11202 | 0,11709 |
| 200 | 0,11356 | 0,11831 |
| 300 | 0,11356 | 0,11831 |
| 400 | 0,11356 | 0,11831 |
| 500 | 0,11581 | 0,11995 |
На графике, показанном на рис.3 ось X представляет количество соседей, а ось Y представляет общедоступный и частный набор данных. Оценка частного набора данных улучшается с 3 соседей до 5 соседей. Оценка общедоступного набора данных улучшается с 3 соседей до 10 соседей. Впоследствии обе оценки уменьшаются по мере увеличения числа соседей.
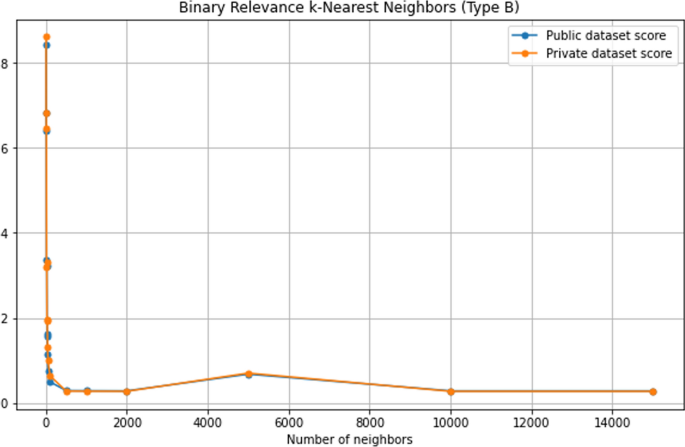
БРкНН-б (тип Б)
Сначала BRkNN-b оценивает «s» (средний размер) наборов меток k ближайших соседей, а затем выводит целое число, ближайшее к «s» меткам, имеющим наибольшую достоверность. Для этой модели на рис. 4 и графике 4 показаны график и оценки прогноза соответственно. На графике, показанном на рис.4 ось X представляет количество соседей, а ось Y представляет оценку общедоступного и частного набора данных. И оценка частного набора данных, и оценка общедоступного набора данных улучшаются с 3 соседей до 2000 соседей. 5000 соседей дают худший результат. После этого обе оценки остаются постоянными. Как видно из таблицы 4 максимальная разница между оценкой общедоступного набора данных и оценкой частного набора данных составляет 0,38482, что происходит, когда количество соседей равно 30.
График, представляющий точность модели ML-KNN
Слои пользовательской нейронной сети
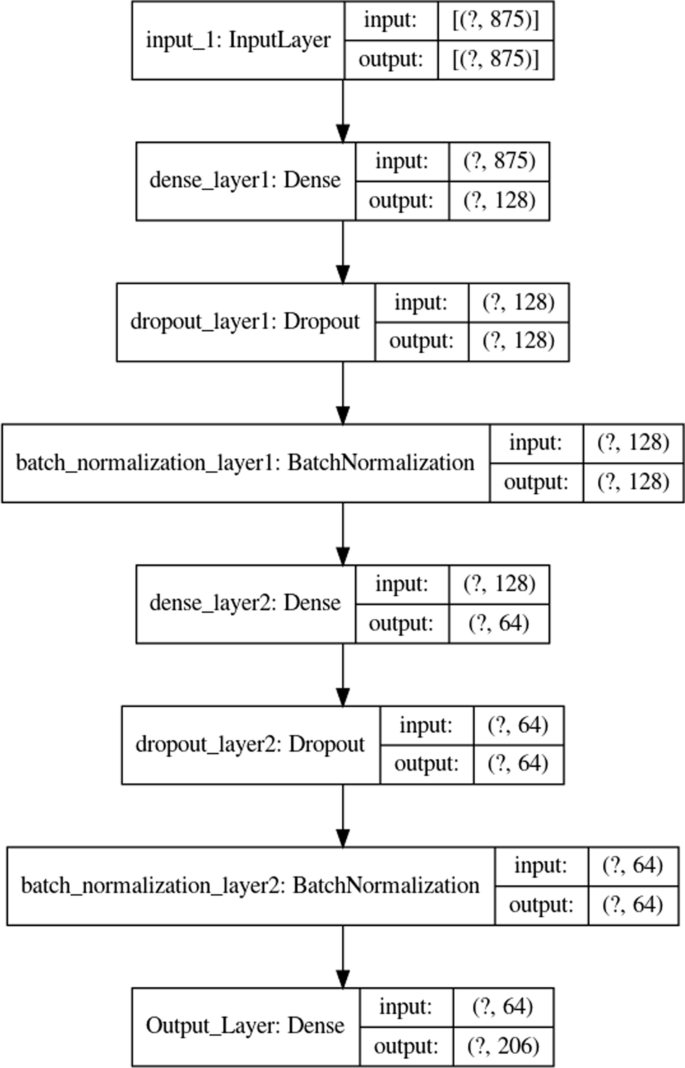
Таблица 6 Описание слоев пользовательской нейронной сети
| Слой | Выходная форма | Количество параметров |
|---|---|---|
| Входной слой | (Нет, 875) | 0 |
| Плотный слой 1 | (Нет, 128) | 112 128 |
| Выпадающий слой 1 | (Нет, 128) | 0 |
| Уровень пакетной нормализации 1 | (Нет, 128) | 512 |
| Плотный слой 2 | (Нет, 64) | 8256 |
| Выпадающий слой 2 | (Нет, 64) | 0 |
| Уровень пакетной нормализации 2 | (Нет, 64) | 256 |
| Выходной слой | (Нет, 206) | 13 390 |
Таблица 7 Функция активации, используемая для пользовательской нейронной сети
| Слой | Функция активации |
|---|---|
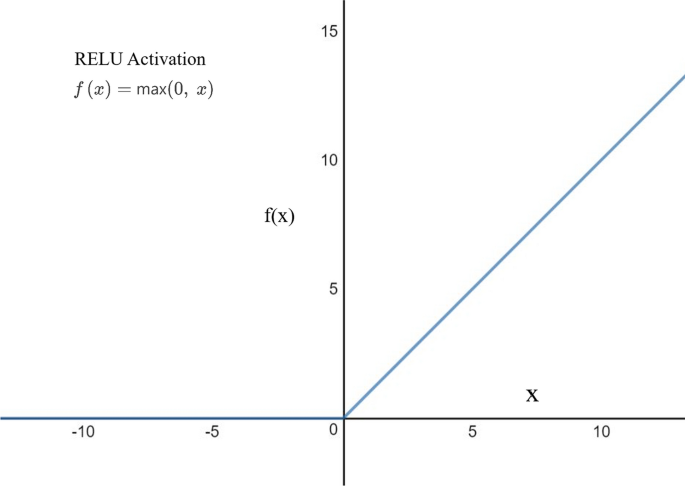
| Плотный слой 1 | РЕЛУ |
| Плотный слой 2 | РЕЛУ |
| Выходной слой | сигмовидная |
График сигмовидной функции активации
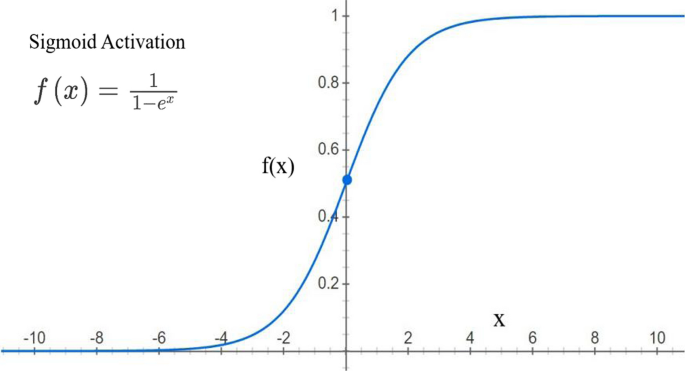
График для функции активации RELU
График, представляющий точность пользовательской нейронной сети
Если у Вас появилась заинтересованность в данной нейронной сети, и она может помочь Вам в реализации Ваших бизнес и других технических задачах, пожалуйста отправьте заявку на email info@ai2b.ru , или позвоните по телефону 8(495)661-61-09




Reviews
There are no reviews yet.