
Description
Создание и экспериментирование с изображениями искусственных цветов с использованием глубоких сверточных сетей GAN.
В 2014 году Ян Гудфеллоу представил генеративно-состязательную сеть (GAN) как новый метод создания выборок из целевого распределения вероятностей, набор данных из которого уже доступен. GAN работает на основе состязательного процесса, в котором два модуля, называемые генератором и дискриминатором, противопоставляются друг другу в минимаксной теоретико-игровой обстановке, при этом генератор создает выборки «фальшивых» данных, а дискриминатор различает их. реальные и поддельные данные. На каждом шаге генератор обновляет свои образцы таким образом, чтобы он мог «обмануть» дискриминатор, классифицируя их как подлинные. После достаточного количества шагов, если предоставленный набор данных достаточно велик и архитектуры в обоих блоках подходят, выборки, сгенерированные генератором, начинают напоминать реальные данные,
Гудфеллоу доказал, что в идеальных условиях (бесконечное количество реальных данных) игра сходится, при этом генератор генерирует выборки, неотличимые от реальных выборок, а дискриминатор полностью путается между двумя классами данных. Хотя игра редко сходится в практических ситуациях, было показано, что GAN и их модификации являются эффективными моделями генерации данных, а их образцы с достаточной точностью напоминают реальность.
DCGAN (Deep Convolutional GAN), разработанный Алеком Рэдфордом, Люком Метцем и Сумитом Чинтала (2016), широко использовался для создания изображений. В этой модели каждый из генератора и дискриминатора представляет собой нейронную сеть глубокой свертки (CNN). В DCGAN было включено несколько архитектур, дополнительных функций и модификаций, и было обнаружено, что он хорошо работает с большинством популярных наборов данных изображений.
В этой статье мы поэкспериментируем с двумя версиями архитектуры DCGAN и двумя разными версиями набора данных, состоящего из изображений разных видов цветов. Первый набор данных (цветы-17) состоит всего из 1360 изображений 17 разновидностей цветов, а второй набор данных (цветы-102) состоит из 8189 изображений 102 разновидностей цветов. Таким образом, помимо эмпирического изучения эффектов настройки гиперпараметров и изменения архитектуры, мы также увидим уровень различий в производительности, вызванный расширением набора обучающих данных.
Файлы загружаются как файлы .tgz tar и должны быть выгружены как изображения. Это делается с помощью библиотеки tarfile Python. Затем изображения считываются как массивы пикселей с помощью библиотеки OpenCV2 , изменяются и объединяются в единый тензор, который можно легко передать в нейронные сети.
Обратите внимание, что для работы кода в рабочем каталоге должен быть создан необходимый пустой текстовый файл «flowers102.txt».
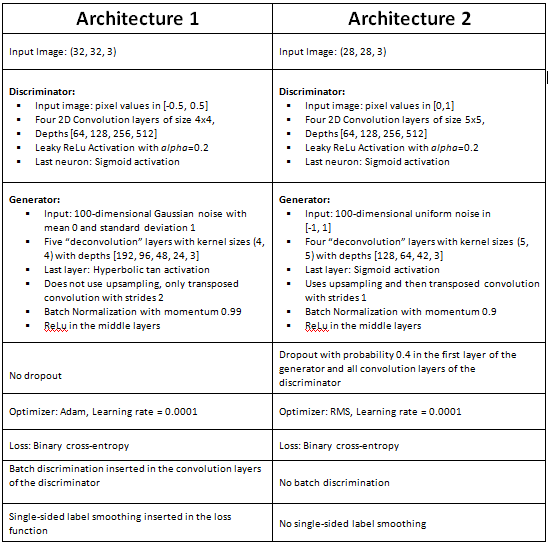
Как только изображения подготовлены в виде тензоров, мы можем начать экспериментировать с архитектурой. Во-первых, мы делаем краткий обзор двух архитектур. Ясно, что основные отличия заключаются в отсутствии одностороннего сглаживания меток и групповой дискриминации во второй архитектуре и отсева в первой. Генератор первой архитектуры также является слоем глубже, чем генератор второй.
Начнем с рассмотрения результатов архитектуры 2 в наборе данных с 17 метками. Поскольку исходный набор данных содержит большинство желтых и фиолетовых цветов, GAN перешел в режим коллапса, сгенерировав только эти цвета. Ниже приведены результаты в конце 10000-й эпохи.

Сравните это с результатами, когда в качестве входных данных использовалась только выбранная партия набора данных. В таком случае в выходных изображениях получается больше цветов.

Несмотря на то, что во втором случае размер набора данных уменьшается, качество изображений более или менее одинаково. Фактически, результирующие изображения не сильно отличаются, даже если набор входных данных содержит только цветы с одной этикеткой, как показано ниже:

Это показывает, что GAN получает только очень небольшое подмножество функций из реальных данных и попадает в режим коллапса. Вот почему увеличение размера набора данных не улучшает его производительность. Таким образом, архитектура-2 требует модификации для решения этой проблемы. Пакетная дискриминация и одностороннее сглаживание меток обычно рекомендуются для решения этой проблемы и используются в архитектуре-1.
Можно ожидать, что качество изображения повысится, если вводятся изображения в градациях серого, потому что проблема кажется упрощенной, поскольку количество входных параметров уменьшается втрое (меньшее количество параметров, что облегчает обучение). Однако качество изображения в этом случае не улучшается.

Все приведенные выше результаты получены, когда скорости обучения дискриминатора и генератора установлены равными. Когда скорость обучения дискриминатора удваивается, как это иногда делается в GAN, проблема коллапса режима усугубляется, и иногда генерируются изображения только одного цвета (желтого или фиолетового). С другой стороны, это немного повышает резкость изображений в градациях серого.
Теперь перейдем к архитектуре-1. Изображение ниже демонстрирует, что эта DCGAN превосходит описанную выше с точки зрения четкости цветов, а также разнообразия:

Приведенные выше изображения были сгенерированы с использованием размера пакета 16. Было обнаружено, что увеличение размера пакета (до 32), а также его уменьшение (до 8) ухудшают результирующие изображения. Обратите внимание, что в модели смешаны черты разных сортов цветов для создания новых. Есть несколько созданных цветов, которые имеют смешение цветов (половина цветка фиолетовая, плавно переходящая в другую половину, белую).
Также обратите внимание, что проблема коллапса режима резко уменьшилась, теперь белые цветы генерируются в равной пропорции с желтыми и фиолетовыми. Это результат использования пакетной дискриминации и одностороннего сглаживания этикеток. Одной из возможных причин, по которой архитектура-1 генерирует относительно более гладкие и менее пиксельные изображения, является использование двойных шагов, а не повышение дискретизации вместе с транспонированной сверткой, как это используется в архитектуре-2. Другой возможностью является наличие в генераторе лишнего транспонированного сверточного слоя. Если в первую архитектуру ввести отсев, то ее производительность сильно ухудшается, а сгенерированные изображения имеют размытые участки в нескольких областях.
Был проведен ряд различных экспериментов: изменение сглаживания меток с (0,1, 0,9) на (0,2, 0,8), удвоение веса пакетной дискриминации и его полное удаление, изменение оптимизаторов и типов шума (между гауссовым и равномерным) и т.д. В большинстве случаев в результатах наблюдались небольшие изменения, но они носили номинальный характер.
Теперь мы используем архитектуру-1 в большом наборе данных flowers-102. Вероятно, поскольку этот набор данных намного больше, размер пакета 16 не дает наилучших результатов. Изображения улучшаются с увеличением размера пакета, по крайней мере, до размера 64:

Приведенный выше результат получен после запуска DCGAN (архитектура-1) в течение 20 000 эпох, хотя результаты более или менее такие же после 15 000-й эпохи. Повсюду мы измеряем «хорошесть» наших результатов только визуально. Другой способ сделать это — просмотреть прогнозы дискриминатора на реальных данных и сгенерированных изображениях. В идеальном сценарии, когда игра достигла сходимости, оба эти числа должны быть равны 0,5. Это сближение, конечно, не достигается в действительности.
Однако по истечении 20 000 эпох цифры разумны и варьируются от 0,1 до 0,9 для архитектуры-1. Для архитектуры-2 результаты гораздо ближе к 1, так как набор данных (цветы-17) меньше, сгенерированные изображения недостаточно близки к реальным, и нет сглаживания меток: таким образом, дискриминатор высоко уверен его настоящая/фальшивая классификация.
Изображения можно дополнительно повысить резкость, добавив к результатам генератора случайный гауссов шум, интенсивность которого уменьшается с увеличением эпохи. Окончательные результаты:

Если у Вас появилась заинтересованность в данной нейронной сети, и она может помочь Вам в реализации Ваших бизнес и других технических задачах, пожалуйста отправьте заявку на email info@ai2b.ru , или позвоните по телефону 8(495)661-61-09



Reviews
There are no reviews yet.