Какие методы используются для классификации видео? Каковы его самые большие проблемы и как их преодолеть? А как построить видеоклассификатор? Давай выясним.
В связи с быстрым ростом видеоконтента в Интернете классификация видео стала важной задачей компьютерного зрения. Классификация видео имеет широкий спектр применений во многих отраслях: от идентификации действий человека на видео наблюдения до понимания содержания видео для поиска и рекомендации.
В этой статье мы рассмотрим различные методы, используемые для классификации видео. Мы также обсудим проблемы, связанные с классификацией видео, и способы их преодоления. Независимо от того, являетесь ли вы исследователем компьютерного зрения, инженером по машинному обучению или просто человеком, интересующимся этой темой, эта статья вам пригодится.
В этой статье мы рассмотрим:
Что такое классификация видео?
Наборы данных классификации видео
Методы классификации видео
Варианты использования классификации видео
Как создать видеоклассификатор с помощью V7?
Что такое классификация видео?
Классификация видео — быстро развивающаяся область компьютерного зрения и машинного обучения . Подобно классификации изображений , классификация видео включает в себя сортировку видео по соответствующим категориям, таким как выполняемые действия (например, танцы, ходьба, бег) или поведенческие эмоции (например, веселый, грустный, удивленный).
Однако в то время как изображения классифицируются на основе пространственного содержания (например, изображение человека или изображение собаки), видео необходимо классифицировать как на основе их пространственного, так и временного (временного) содержания, поскольку два видео может содержать одного и того же человека (одну и ту же пространственную информацию), совершающего разные действия (разница во временном содержании).
Одной из ключевых проблем классификации видео является огромный объем данных, которые необходимо обработать. Видео обычно состоит из большого количества кадров, каждый из которых содержит большое количество информации. Что еще больше усложняет ситуацию, видео также можно снимать в разных условиях освещения, под разными углами и с разной частотой кадров. Вот наиболее распространенные проблемы с классификацией видео:
- Масштабируемость: поскольку объем видеоданных продолжает расти, становится все сложнее обрабатывать и классифицировать их за разумное время. Это особенно проблематично для подходов глубокого обучения , которые требуют больших объемов данных и вычислительных ресурсов для обучения.
- Обобщение. Многие алгоритмы классификации видео предназначены для работы с конкретным набором данных или задачей, но могут плохо обобщаться на другие наборы данных или задачи.
- Видеоаннотации. Маркировка больших объемов видеоданных — трудоемкая и трудоемкая задача. Это может затруднить получение больших высококачественных наборов данных для обучения и оценки алгоритмов классификации видео, особенно моделей обучения с учителем .
- Конфиденциальность и безопасность. Использование видеоданных вызывает ряд проблем конфиденциальности и безопасности, особенно когда речь идет о наблюдении и распознавании лиц. Также существуют опасения по поводу возможного неправомерного использования видеоданных, например, в случае с видео DeepFake.
- Качество видео. Видео могут иметь различное качество и форматы, что может быть сложно обрабатывать и отрицательно влиять на производительность видеоклассификатора.
Чтобы преодолеть эти проблемы, для классификации видео были разработаны различные методы и алгоритмы, большинство из которых используют глубокое обучение для автоматизации.
Наборы данных классификации видео
Наборы данных классификации видео с открытым исходным кодом предоставляют исследователям помеченные видеоданные, которые можно использовать для обучения и оценки моделей классификации видео. Существует несколько открытых наборов данных для классификации видео, что помогает исследователям стандартизировать свои модели и сравнивать их с существующими современными моделями.
Некоторые из наиболее широко используемых наборов данных для классификации видео:
- UCF101 : Одним из наиболее широко используемых наборов данных для классификации видео является набор данных UCF101, который состоит из 13320 видео из 101 различного класса действий, таких как ходьба, бег трусцой и игра в футбол. Набор данных обычно используется для оценки производительности алгоритмов классификации видео в широком спектре задач распознавания действий. UCF101 также имеет несколько дочерних наборов данных, которые являются его подмножествами, содержащими меньшее количество или некоторые определенные классы действий, например UCF50 , UCF11 (YouTube Action) , UCF Aerial Action и т. д.
- HMDB51 : Этот набор данных содержит 6849 видео из 51 различного класса действий. Этот набор данных похож на UCF101, но в нем меньше классов и видео. Поэтому он больше подходит для менее сложных моделей (например, для точной настройки моделей учащихся в конвейерах дистилляции знаний ).
- Кинетика : Кинетика — еще один популярный набор данных для классификации видео, состоящий из более чем 400 000 видео из 600 классов действий человека. Видео в наборе данных Kinetics взяты с YouTube и других источников и помечены аннотаторами.
- YouTube-8M : YouTube-8M — это еще один крупномасштабный набор данных, включающий 8 миллионов URL-адресов видео YouTube и связанных с ними ярлыков из словаря, состоящего из 4716 классов. В отличие от предыдущих, этот набор данных не предназначен специально для распознавания действий, но охватывает широкий спектр задач классификации видео.
- Sports-1M : этот набор данных для распознавания спортивных действий содержит 1 миллион видеороликов из 487 видов спорта, таких как баскетбол, футбол и хоккей.
Помимо общедоступных наборов данных, исследователи также создают свои собственные наборы данных для конкретных исследовательских проектов. Это может быть особенно полезно, когда в доступных наборах данных нет необходимых классов или достаточного количества образцов для конкретной исследовательской задачи.
Важно отметить, что качество и размер набора данных могут сильно повлиять на производительность алгоритмов классификации видео. Наборы данных большего размера и с более разнообразными классами, как правило, приводят к повышению производительности, поскольку они предоставляют модели более разнообразные примеры и улучшают возможности модели по обобщению.
💡 Совет для профессионалов: ознакомьтесь с коллекцией V7, состоящей из более чем 500 открытых наборов данных.
Методы классификации видео
За прошедшие годы для классификации видео было разработано несколько различных типов алгоритмов глубокого обучения. Большинство из них используют контролируемое обучение — структуру, которая использует видео и их метки для обучения нейронной сети ( сверточные нейронные сети или рекуррентные нейронные сети ). Однако последние методы направлены на снижение зависимости от маркированных данных, поскольку их сложно и дорого собирать.
Хотя на бумаге методы низкого надзора кажутся идеальными, в большинстве случаев за них приходится платить точностью. Таким образом, вопрос о том, использовать ли методы контролируемого или низкого контроля, зависит от варианта использования. В чувствительных приложениях, таких как наблюдение и здравоохранение , точность важнее вычислительной нагрузки. С другой стороны, распознавание спортивных действий или действий общего назначения (например, развлечений) может работать с моделями сравнительно меньшей точности. Им по-прежнему нужны эффективные решения для хранения данных, поскольку в таких доменах часто доступны большие объемы немаркированных данных.
Давайте далее рассмотрим методы классификации видео с контролируемым и низким контролем.
Контролируемый
Обучение с учителем — это тип машинного обучения, при котором модель обучается делать прогнозы на основе помеченных данных. Набор помеченных данных разделяется на обучающие, проверочные и тестовые наборы для оценки модели. Затем обученная модель используется на немаркированных данных для качественной проверки производительности модели. В контексте классификации видео обучение с учителем можно использовать для обучения модели распознаванию конкретных объектов, действий или сцен в видео.
Ранние попытки классификации видео на основе контролируемого обучения включают в себя эту статью , в которой подробно изучались модели CNN для этой задачи в то время, когда CNN приобрели популярность для распознавания изображений .
Однако CNN требуют очень длительных периодов обучения для эффективной оптимизации миллионов параметров модели. Эта трудность возрастает при временном расширении связности архитектуры — сеть должна обрабатывать не одно изображение, а несколько кадров видео одновременно.
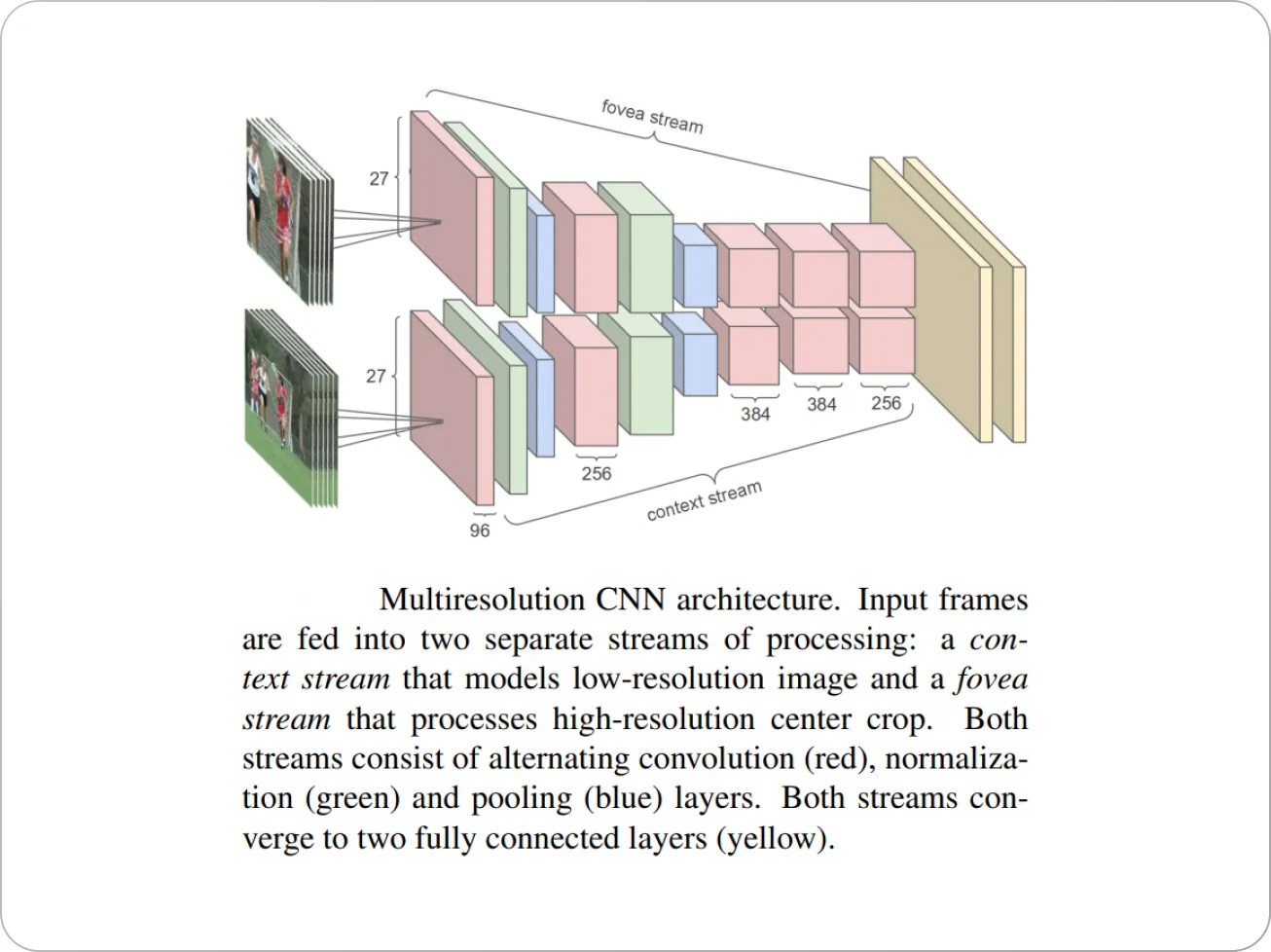
Авторы статьи модифицировали архитектуру CNN, чтобы она содержала два отдельных потока обработки: поток « контекста », который изучает функции в кадрах с низким разрешением, и поток « фовеа » с высоким разрешением, который работает только со средней частью кадра. , что дало прирост производительности в 2–4 раза.
Авторы изучили несколько подходов к объединению информации во временной области (рисунок ниже): объединение может быть выполнено на ранней стадии в сети путем изменения сверточных фильтров первого уровня для расширения во времени, или это может быть сделано позже, путем размещения двух отдельных одиночных фильтров. сети создают кадры на некотором расстоянии друг от друга и объединяют их результаты позже в процессе обработки.

Кроме того, авторы изучили CNN с несколькими разрешениями (рисунок ниже), чтобы ускорить время обучения CNN с 5 клипов в секунду до 20 клипов в секунду, сохранив при этом производительность.
Вот некоторые качественные результаты, полученные авторами с помощью их модели:

Полуконтролируемый
Обучение с полуконтролем — это парадигма машинного обучения, в которой модель обучается как на помеченных, так и на неразмеченных данных. В таких случаях обычно процент помеченных данных в наборе данных невелик (например, 5% или 10%) и используется экономно, в то время как большой объем неструктурированных данных легко доступен.
VideoSSL — это платформа, которая пытается классифицировать видео с использованием полуконтролируемого обучения. Учитывая небольшую часть аннотированных обучающих выборок, VideoSSL использует два управляющих сигнала, извлеченных из немаркированных данных, для повышения производительности классификатора:
- Псевдометки неразмеченных 3D-видеоклипов
- Признаки внешнего вида интересующих объектов, полученные путем прогнозирования классификатором 2D-изображений CNN на случайном видеокадре.
Обзор структуры показан ниже.

Вот несколько примеров качественных результатов, полученных VideoSSL:

Слабо контролируемый
Классификация видео со слабым контролем — это тип задачи машинного обучения, которая включает в себя обучение модели классификации видео на основе слабых меток, т. е. точные метки классификации недоступны, но может быть некоторая другая полезная информация. В этом отличие от полностью контролируемой классификации видео, где модель обучается с использованием большого количества размеченных данных, включая метки классов каждого кадра или сегмента видео.
Примером такой структуры является модель UntrimmedNet , которая решает проблему распознавания действий из необрезанных необработанных видео. Здесь слабыми метками являются аннотации уровня видео (скажем, боулинг, бег и т. д.), а цель — выполнить временную аннотацию, т. е. найти временные метки, между которыми происходит фактическое действие в видео.
UntrimmedNet состоит из двух компонентов: модуля классификации и модуля выбора . UntrimmedNet начинается с создания предложений клипов, которые могут содержать экземпляры действий, с использованием унифицированной выборки или выборки на основе кадров, которая передается в глубокую сеть для извлечения признаков. На основе этих представлений на уровне клипа модуль классификации пытается спрогнозировать оценки классификации для каждого предложения клипа. Напротив, модуль выбора пытается выбрать или ранжировать эти предложения клипов.
Результаты двух модулей объединяются с взвешенной по вниманию суммой продуктов для создания временной аннотации. Рабочий процесс модели UntrimmedNet показан ниже.

Самоконтролируемый
Самостоятельное обучение — это уникальный подход к машинному обучению без присмотра, при котором модель при получении выборки обучающих данных генерирует (псевдо) метки. Из этих псевдометок те, которые были предсказаны с высокой достоверностью, используются в качестве основной истины для следующей итерации алгоритма обучения. Таким образом, весь набор обучающих данных помечается, и сеть становится достаточно обученной, что затем оценивается на тестовом наборе.
Примером такого подхода является платформа Самоконтролируемого видеотрансформатора (SVT) , которая использует Vision Transformer (ViT) в условиях самоконтролируемой фильтрации знаний . Короче говоря, дистилляция знаний включает в себя обучение более простой модели для конкретной задачи (сети учеников) с помощью изученной семантики с помощью сложной модели (сети учителей), обученной для задач общего назначения.
SVT обучает модели учеников и учителей с целью сходства, которая сопоставляет представления признаков в пространственных и временных измерениях с помощью механизмов внимания к пространству и времени. Авторы достигают этого, создавая позитивные пространственно-временные представления, которые различаются по пространственным размерам и выбираются в разные временные рамки из одного видео. Рабочий процесс платформы SVT показан ниже.

Во время обучения параметры видеотрансформатора преподавателя обновляются как экспоненциальное скользящее среднее видеотрансформатора ученика. Обе эти сети обрабатывают разные пространственно-временные представления одного и того же видео, а целевая функция SVT предназначена для прогнозирования одного просмотра относительно другого в пространстве признаков. Это позволяет SVT изучать надежные функции, которые инвариантны к пространственно-временным изменениям в видео, одновременно генерируя отличительные функции для разных видео.
В отличие от контрастных методов обучения, SVT не требует анализа отрицательных классов и может эффективно сходиться всего за 20 итераций, достигая при этом самых современных результатов (как показано ниже).
%20results.webp)
Варианты использования классификации видео
Классификация видео имеет широкий спектр применений в различных областях, включая развлечения, безопасность, наблюдение, здравоохранение и образование. Давайте кратко рассмотрим некоторые из наиболее распространенных случаев использования.
Признание человеческой деятельности
Классификация видео для распознавания человеческой деятельности включает анализ видео людей для идентификации и классификации действий, которые они выполняют. Это может включать в себя такие виды деятельности, как ходьба, бег, прыжки и даже более сложные занятия, такие как занятия спортом или танцы.
Модель преобразователя действий является примером структуры, которая решает проблему распознавания действий. Авторы предположили, что контекстная информация помогает повысить производительность модели — например, обнаружить, что человек говорит, легче, когда в видео присутствует другой человек.
Структура преобразователя действий состоит из отдельных «базовых» и «головных» сетей. Базовая сеть представляет собой 3D CNN для генерации функций и предложений регионов для людей, присутствующих на видео. Головная сеть представляет собой модифицированную архитектуру преобразователя для классификации действий интересующих людей с использованием карт признаков базовой сети. Схематический обзор модели представлен ниже.

Вот некоторые результаты, полученные с помощью модели преобразователя действия.
Здравоохранение
Классификация видео может использоваться в секторе здравоохранения для автоматического анализа медицинских видеороликов, таких как записи эндоскопии или хирургических операций, для обнаружения и классификации отклонений или для помощи в диагностике и планировании лечения.
Например, в этой статье используются 3D-архитектуры CNN для автоматической интерпретации ультразвуковых видеороликов сердца. Авторы считают, что для решения этой проблемы лучше всего подходят двухпотоковые сети CNN, где один поток кодирует пространственную информацию каждого кадра видео, а второй поток кодирует временную информацию.

Ниже показан пример производительности двухпотоковой модели, полученный авторами, где карты значимости, полученные на основе сетевых потоков, подчеркивают особенности видео, которые больше всего влияют на производительность модели CNN. На пространственный поток влияют анатомические границы значимых структур, тогда как движение клапанов легочной артерии влияет на временной поток.

Автономные транспортные средства
Модель глубокого обучения, обученная для классификации видео, может использоваться для обнаружения и отслеживания других транспортных средств на дороге, позволяя автономному транспортному средству принимать решения о том, когда сменить полосу движения или выехать на шоссе. Аналогичным образом модель можно использовать для идентификации пешеходов и других объектов на пути транспортного средства, что позволяет транспортному средству предпринимать соответствующие действия во избежание столкновений.
Модель FCN-LSTM является примером системы, которая использует комбинацию полностью сверточной сети (FCN) для кодирования визуальных объектов и сети долгосрочной краткосрочной памяти ( LSTM ) для кодирования временных объектов.
Модель FCN-LSTM способна совместно обучать прогнозированию движения и контролируемым задачам на уровне пикселей. Семантическая сегментация используется как дополнительная задача в соответствии с парадигмой «привилегированного» обучения информации для дополнительного повышения производительности при планировании движения. Схематический обзор модели представлен ниже.

Вот несколько примеров прогнозов, сделанных сетью FCN-LSTM.

Воплощенный искусственный интеллект (робототехника)
Классификация видео может использоваться для классификации объектов, сцен и действий в режиме реального времени в среде робота и предоставления соответствующих инструкций по навигации.
Например, в этой статье используется архитектура рекуррентной нейронной сети (RNN) и CNN для извлечения признаков из видеокадров для классификации видео и генерации естественных текстовых команд для роботизированных манипуляций.
Платформа разбивает видео на кадры и извлекает из каждого из них функции CNN. Затем два слоя RNN используются для изучения взаимосвязи между визуальными функциями и командой вывода. Однако, в отличие от типичных проблем с субтитрами для видео, которые описывают выходное предложение в форме естественного языка, авторы использовали форму без грамматики для описания выходной команды. Схема работы модели показана ниже.

Вот несколько примеров выходных команд, полученных моделью с учетом входной видеопоследовательности.

Затем авторы создали роботизированную структуру, которая позволяет их роботу «WALK-MAN» выполнять различные манипуляционные задачи, просто «просматривая» входное видео, поскольку предыдущая архитектура RNN встроена в роботизированную систему.
Модуль перевода генерирует выходное командное предложение для каждой задачи, представленной входным видео. На основе этой команды робот использует свою систему видения для поиска соответствующих объектов и планирования действий. Два примера этого показаны ниже.

Видео рекомендация
Классификация видео используется для классификации содержимого видео и ориентации на соответствующую аудиторию на основе ее интересов, демографических данных и истории просмотров — приложение, которое мы все знаем по YouTube.
Примером такой системы видеорекомендаций является структура, предложенная в этой статье Google Research. Авторы представили систему рекомендаций видео на основе контента, которая использует необработанные (необрезанные) видео- и аудиоданные ( мультимодальное обучение ). Они моделируют проблему как задачу изучения сходства видео и изучают компактное представление видео, сохраняя его семантику на основе визуальных и аудиосигналов, используя глубокие нейронные сети.
Авторы кодируют все видео в пространство встраивания, где похожие (рекомендуемые) видео расположены близко друг к другу, и показывают, что изученные встраивания выходят за рамки простого визуального и звукового сходства и способны улавливать сложные семантические отношения.

Авторы использовали два типа архитектур, раннее слияние и позднее слияние, для системы рекомендаций, чтобы всесторонне оценить лучшую производительность, и достигли наилучшей производительности, используя метод позднего слияния.
Вот несколько показательных результатов:

Другие приложения
Классификация видео имеет и другие далеко идущие применения. Они используются ежедневно для развлечений — для рекомендаций фильмов или музыки в потоковых сервисах, автоматического редактирования видео или в спорте для анализа производительности игроков.
Классификацию видео также можно использовать для анализа образовательных видеороликов, таких как лекции или учебные пособия, для выявления ключевых понятий или создания сводок контента, а также для автоматического обнаружения и классификации подозрительных или аномальных действий в кадрах наблюдения, таких как драки, праздношатание или воровство. Это может помочь сотрудникам службы безопасности быстро выявить потенциальные угрозы и отреагировать соответствующим образом.Создавайте рабочие процессы ML. Развертывайте ИИ быстрее.
Прокладывайте оптимальные маршруты для своих тренировочных данных с помощью 8 этапов рабочего процесса, которые можно организовать, подключить и зациклить любым удобным для вас способом.
Как создать видеоклассификатор с помощью V7
V7 позволяет легко обучать собственные видеоклассификаторы и другие модели компьютерного зрения. Вы можете оптимизировать свои процессы, управляя аннотациями данных и конвейером машинного обучения в одном месте. Платформа имеет веб-интерфейс, и вы можете тестировать и обучать свои модели в облаке.
Давайте создадим классификатор, который сможет распознавать кадры тенниса, футбола, футбола и баскетбола.
Чтобы создать модель классификации видео вместе с учебным пособием, зарегистрируйте бесплатную учетную запись V7 для студентов и исследователей. Подтвердите свою академию и начните уже сегодня.
Шаг 1. Соберите и загрузите видеоклипы на платформу V7.
Первый шаг — загрузить ваши видеоклипы на платформу V7.
Перейдите на вкладку «Наборы данных» и добавьте новый набор данных с помощью кнопки. Назвав новый набор данных, перетащите файлы.

При загрузке видео вы можете определить частоту кадров в секунду (FPS).

Одной из уникальных особенностей V7 является то, что он позволяет использовать исходную частоту кадров ваших видео для аннотаций данных. Однако, чтобы сохранить управляемость данных, рассмотрите возможность извлечения только нескольких кадров в секунду. Это также отличный способ улучшить вариативность вашего набора данных без увеличения его размера. Лучше использовать 10 разных клипов с 3 FPS, чем из одного видео извлекать 30 FPS.
Нажмите Продолжить , чтобы продолжить.
Шаг 2. Определите набор уникальных классов, которые вы хотите распознать
На следующем шаге мы можем добавить наши собственные классы. Обязательно выберите Тег в качестве типа класса.
Важно использовать имена классов, которые будет легко запомнить и понять. В нашем примере занятиями являются футбол, футбол, теннис и баскетбол.

Теги — это аннотации на уровне изображения. Это означает, что наша модель будет использовать целые кадры в качестве обучающих данных. Это стандартная практика обучения базовых классификационных моделей. Если бы нам нужна была более продвинутая модель (для обнаружения объектов или распознавания активности), лучшим выбором были бы маски сегментации или ограничивающие рамки.
Продолжайте использовать настройки рабочего процесса по умолчанию, чтобы завершить настройку набора данных.
Шаг 3. Присвойте правильные теги своим видеоклипам
Теперь вы можете просматривать свои видео и применять теги, созданные на предыдущем шаге. Выберите видео и подходящий тег для него.
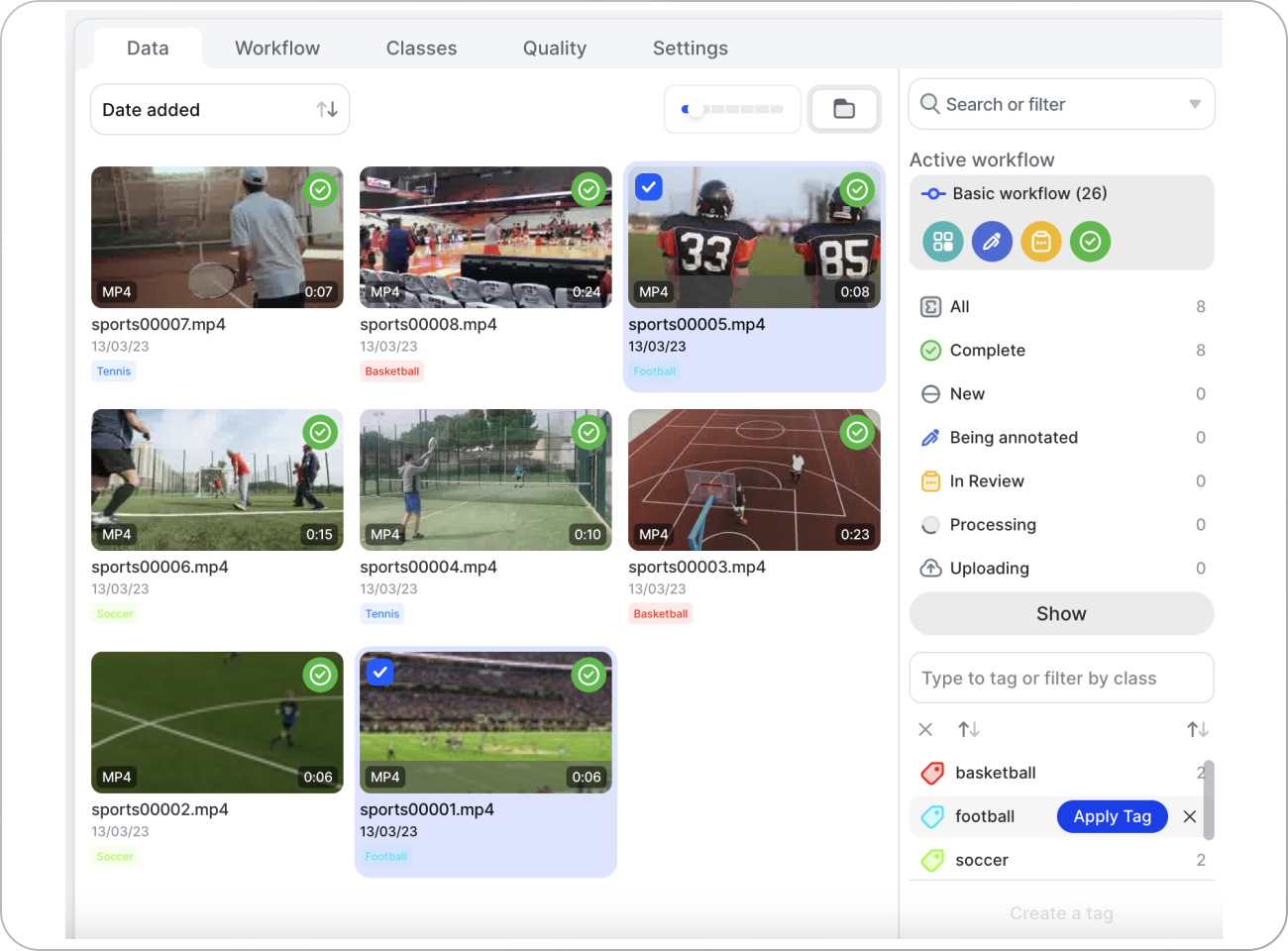
Важно отметить, что при назначении тегов таким образом они будут применены ко всему клипу. Но при желании вы также можете использовать тег только для определенной части видео. Для этого откройте клип и используйте временную шкалу, чтобы настроить диапазон метки тега.

Выбор того, какие кадры следует пометить, особенно полезен, если вы работаете с более длинными материалами. Например, если вы используете запись всего футбольного матча, вы, вероятно, не захотите использовать рекламную паузу в качестве тренировочных данных.
После завершения выберите все файлы и измените их статус (Этап) на Завершено .
Шаг 4. Обучите модель классификации видео с помощью V7
После того, как все ваши видео будут помечены, вы можете перейти на панель «Модели» .

Нажмите кнопку «Обучить модель» , выберите «Классификация» в качестве типа модели и выберите теги, которые вы хотите использовать для обучения.
Настройте свою модель и запланируйте ее обучение. Это может занять от нескольких минут до часа, в зависимости от сложности вашего набора данных.
Шаг 5. Загрузите новый клип и протестируйте свою модель.
Снова откройте вкладку «Модели» и убедитесь, что ваша новая модель работает.

Последний шаг — проверить, правильно ли работает модель.
Для этого перейдите в раздел «Рабочие процессы» и замените этап «Аннотации» новым этапом «Модель» . Затем подключите свою модель.
Вы должны исходить из чего-то вроде этого:

Схема рабочего процесса выглядит следующим образом:

Теперь вы можете добавлять новые элементы в свой набор данных.

Выберите новые файлы и отправьте их на этап модели. Модель классифицирует видео и присвоит правильные теги вместе с оценками достоверности.

Заключительные слова
Классификация видео — быстро развивающаяся область компьютерного зрения, имеющая широкий спектр применений в различных отраслях, от здравоохранения до развлечений. Использование методов глубокого обучения значительно улучшило производительность моделей классификации видео, позволив им достичь высокой точности и надежности.
Тем не менее, эта область по-прежнему сталкивается с рядом проблем, таких как необходимость в больших объемах размеченных данных и сложность обработки временной информации в видео, и именно здесь вступают в игру методы с низким уровнем контроля, которые мы обсуждали. Ожидается, что эта область будет постоянно расширяться за счет новых инноваций, которые требуют меньше данных для обучения (чтобы сэкономить вычислительную нагрузку) и дают более точные результаты, чем могут предоставить сами люди.